Here describe several DNN related subjects covered by Evo engine.
DNN Devices
- Evo engine supports several kinds of devices on which DNN models can be run. As such devices, there is not only typical CPU but also GPU(iGPU/dGPU), VPU(Vision Processing Unit) and so on. These devices can be assigned to not only different engine instances but also the same one. The following image shows an ideal use case of DNN devices.
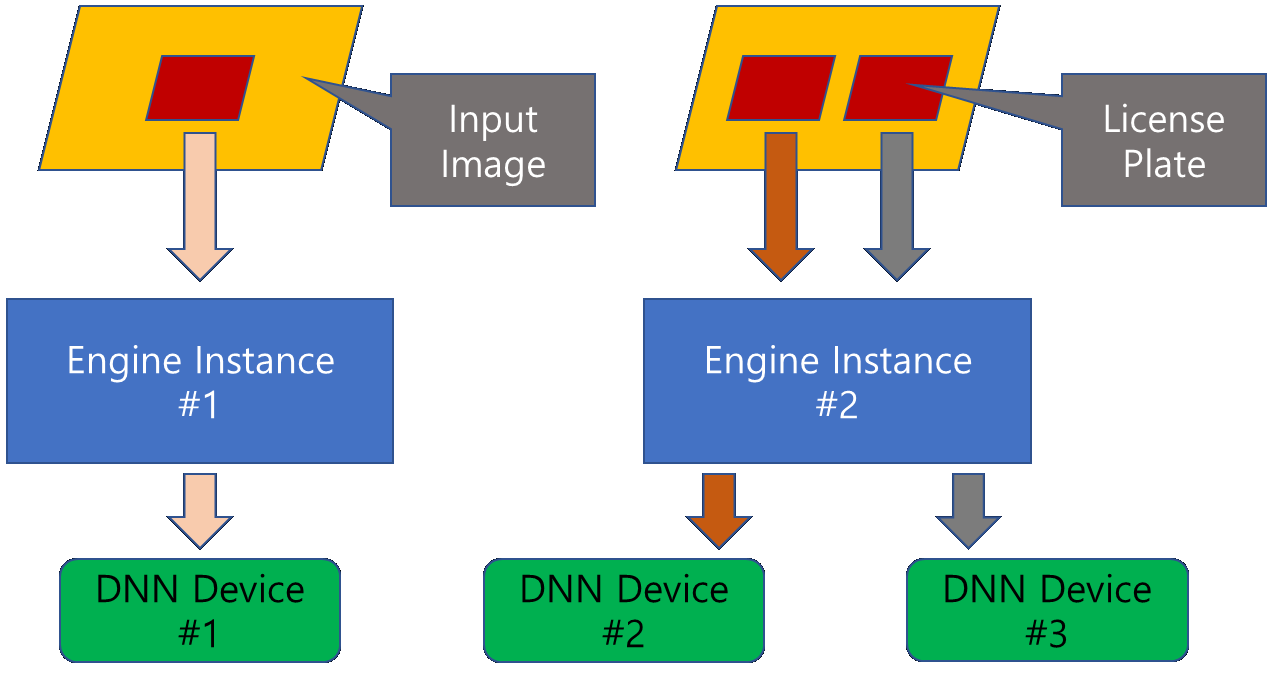
- Warning
- The kinds of DNN devices supported by Evo engine can be changed depending on its version without notification.
DNN Model Data Formats (DMDF)
Evo engine use several inherent DNN models which can be run on DNN devices. They are trained beforehand and provided as a form of model data file, which is included in SDK. The problem here is that each DNN device supports different types of DNN model data formats and different format preferences. In case of CPU, single-precision floting point(FP32), half-precision floating point(FP16) and 8Bit integer(I8) data formats are supported and FP32 data format is prefered to the others. Prefered format of each device has less latency than the others. Following table summarizes information about DMDFs.
DNN Devices DNN Model Data Formats CPU FP32*, FP16, I8 GPU FP32, FP16*, I8 MYRIAD FP16 The '*' marker represents prefered format of the device.
- Note
- The 'I8' format is described above but not supported yet.
DNN Device Descriptors (DDD)
- DNN Device Descriptor is simple string describing one or more DNN devices with their common DMDF and is used when every engine instance is intialized.
- Syntax
- DMDF:DNN-Device[,DNN-Device,...]
Available DMDFs are different depending on DNN devices listed in the descriptor. For example, Both of 'CPU' and 'GPU' support 'FP32' and 'FP16' formats but 'MYRIAD' supports only 'FP16' format. So, if more than 2 devices are used in the descriptor common DMDFs must be specified which all the device can support.
Good) 'FP32:CPU', 'FP32:GPU,CPU', 'FP16:GPU,CPU,MYRIAD' ...
Bad) 'FP32:MYRIAD', 'FP32:GPU,MYRIAD' ...When there are more than two DNN devices and more than two engine instances, each engine instance can use different DDD but it is recommend that all the instances use the same DDD to distribute the load by themselves.
Possible Examples) instance #1: 'FP32:CPU', instance #2: 'FP16:GPU', instance #3: 'FP32:CPU,GPU' ...
Recommended Examples) instance #1: 'FP32:CPU,GPU', instance #2: 'FP32:CPU,GPU' ...The enumeration order of DNN devices in the descriptor has special meaning when more than two devices are used. For example, assume 'FP32:CPU,GPU' is used as DDD and there are more than two engine instances. When the first input image arrives, an instance processes it using CPU. Meanwhile, if the next image arrives before the first one has been completed another instance will process it using GPU.
DNN Run Modes (DRM)
- There are two modes to run DNNs, Latency-Oriented and Throughput-Oriented. The former uses all the execution units (in case of CPU, all the cores) to process single input image. However the latter splits them into several groups and process single one per each group in parallel.
- Latency-Oriented vs. Throughput-Oriented
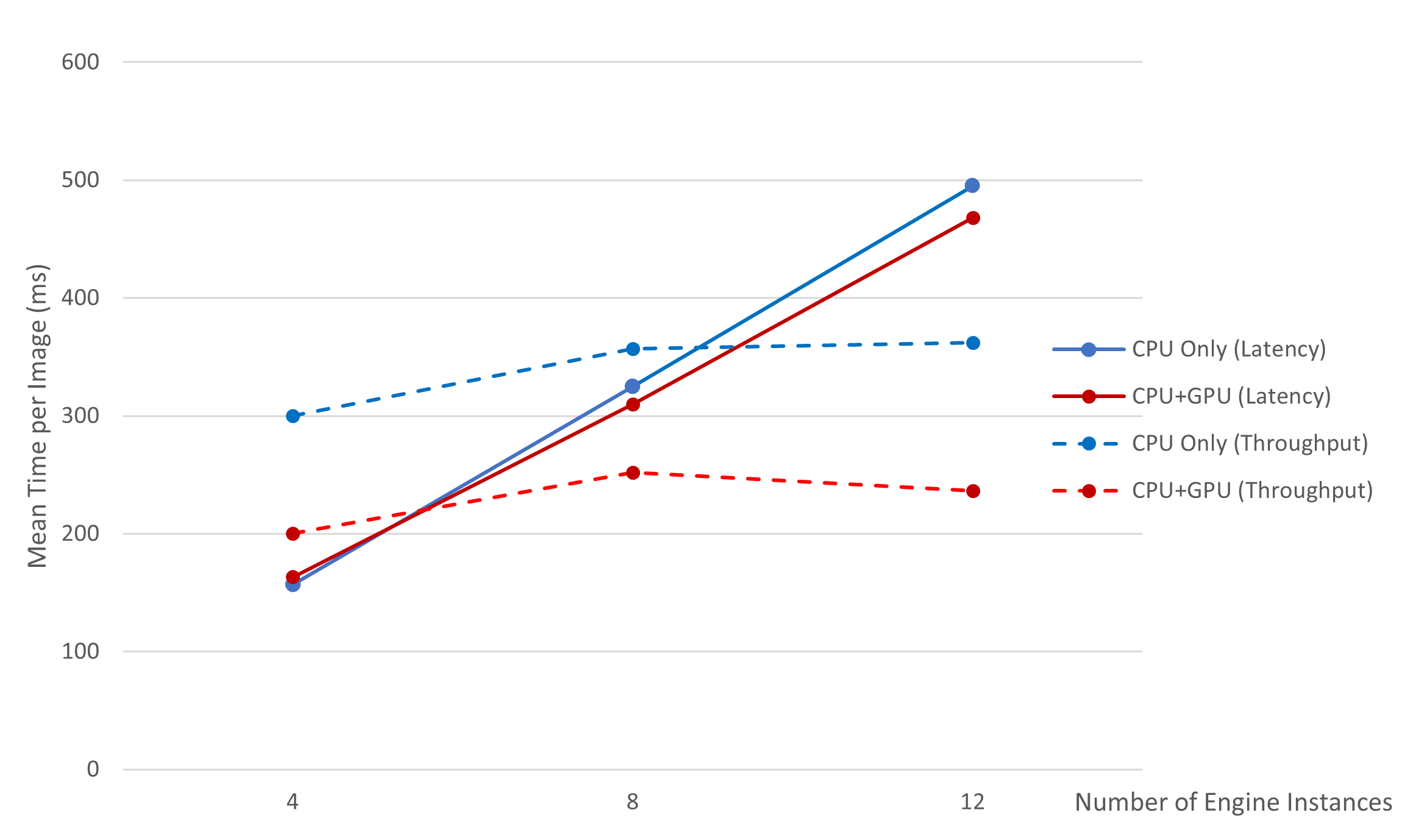
- Latency-Oriented mode is optimized to processing single input image or a few concurrent ones on single or several engine instances, on the other hand, Throughput-Oriented mode is optimized to processing as many concurrent ones as possible on multiple instances. Therefore, appropriate mode must be selected depending on the application environment. Following graph shows test results with respect to concurrent multiple engine instances using Intel's Core 13700K processor and about 400 sample images.
- Descriptor Syntax
- DRM[:parameter(value)[,parameter(value),...]]
- Note
- Upper/lower cases are distinguished and no white space is permitted.
DRM field in the descriptor can become 'latency' or 'throughput' which represents the Latency-Oriented or Throughput-Oriented mode respectively. The parameter fields support currently only 'cpu_threads' to set number of CPU threads which are mobilized to run DNN models. Its default value is '0', which means the number suitable for current system is delegated to the engine. Examples are as follows.
Good) 'latency', 'latency:cpu_threads(5)', 'throughput', 'throughput:cpu_threads(10)' ...
Bad) 'latency:', 'latency:cpu_threads', 'throughput:cpu_threads()' ...In case there are more than two engine instances, the parameter 'cpu_threads' means number of threads shared by all the instances.
